Extending Optimizer in MAC-VO
The IOptimizer Interface
IOptimizer is the interface for the optimizer used in MAC-VO. It is the most complex interface in this project since it allows running any optimizer in sequential/parallel mode according to the config.
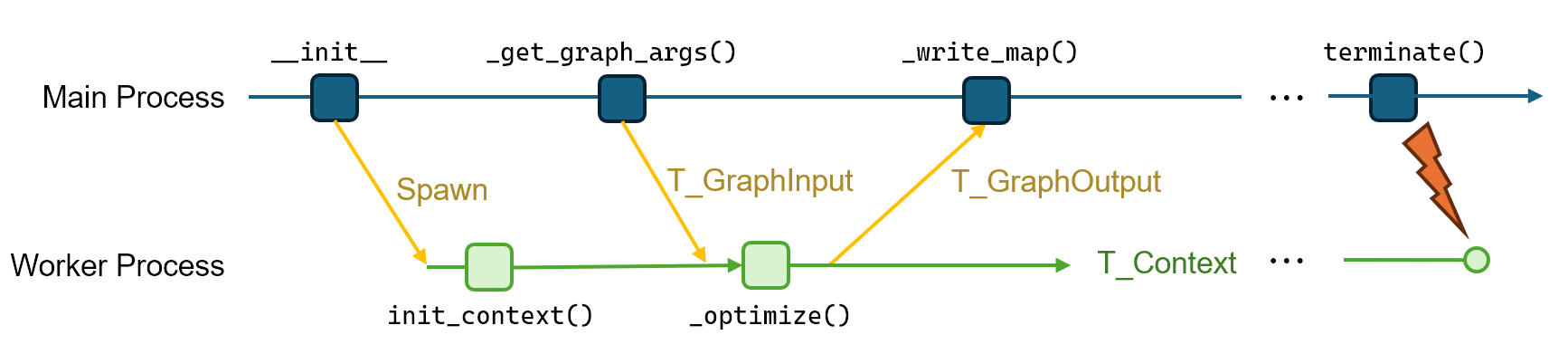
The Optimizer runs in two modes but the user only need to implement a single set of interface, which contains four methods and three data (message) types
Data:
init_context- initialize the "context" of the optimizer. Essentially, context is like theselfin Python but is represented as a separate instance sinceselfcannot be sent directly to the child process._get_graph_args- given the map constructed by odometry and some frames to optimize on, this method extracts all information required to build the optimization problem._optimize- Given context and argument, construct the optimization problem, solve it, and return the updated context and result._write_map- Given the result returned from_optimize, update the map (write the result back to the map)
Data (Message) Type:
T_Context- an arbitrary class that stores the optimizer state accumulated/modified across frames.T_GraphInput- a subclass ofITransferablesince this message may be communicated across processes. Contains all the data required to construct the optimization problem.T_GraphOutput- a subclass ofITransferablesince this message may be communicated across processes. Contains results (of interest) for the optimization problem.
Detailed specification of methods to be implemented is provided below:
Module/Optimization/Interface.py
class IOptimizer(ABC, Generic[T_GraphInput, T_Context, T_GraphOutput], SubclassRegistry):
"""
Interface for optimization module. When config.parallel set to `true`, will spawn a child process
to run optimization loop in "background".
`IOptimizer.optimize(global_map: TensorMap, frames: BatchFrames) -> None`
* In sequential mode, will run optimization loop in blocking mannor and retun when optimization is finished.
* In parallel mode, will send optimization job to child process and return immediately (non-blocking).
`IOptimizer.write_back(global_map: TensorMap) -> None`
* In sequential mode, will write back optimization result to global_map immediately and return.
* In parallel mode, will wait for child process to finish optimization job and write back result to global_map. (blocking)
`IOptimizer.terminate() -> None`
Force terminate child process if in parallel mode. no-op if in sequential mode.
"""
### Internal interface to be implemented
@abstractmethod
def _get_graph_args(self, global_map: TensorMap, frames: BatchFrame) -> T_GraphInput:
"""
Given current global map and frames of interest (actual meaning depends on the implementation),
return T_GraphArgs that will be used by optimizer to construct optimization problem.
"""
...
@staticmethod
@abstractmethod
def init_context(config) -> T_Context:
"""
Given config, initialize a *mutable* context object that is preserved between optimizations.
Can also be used to avoid repetitive initialization of some objects (e.g. optimizer, robust kernel).
"""
...
@staticmethod
@abstractmethod
def _optimize(context: T_Context, graph_args: T_GraphInput) -> tuple[T_Context, T_GraphOutput]:
"""
Given context and argument, construct the optimization problem, solve it and return the
updated context and result.
"""
...
@staticmethod
@abstractmethod
def _write_map(result: T_GraphOutput | None, global_map: TensorMap) -> None:
"""
Given the result, write back the result to global_map.
"""
...
Below we demonstrate how the internal interfaces mentioned above are orchestrated in sequential and parallel optimization mode.
Parallel Mode
Sequential Mode
